Introduction to pileup
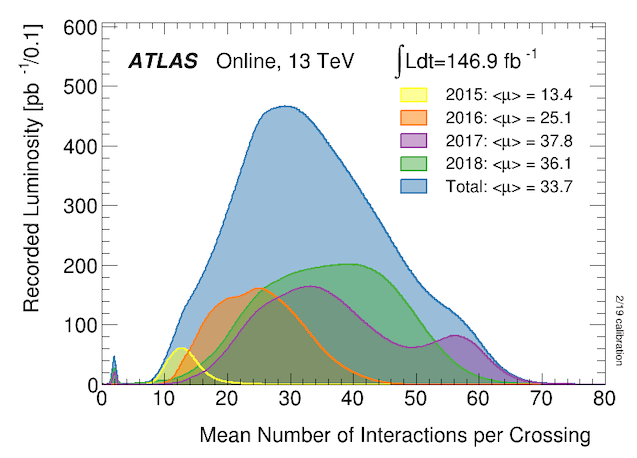
Protons (and heavy ions) are collided in ATLAS in bunches, resulting in multiple simultaneous collisions in every bunch crossing. This is referred to as pileup. Pileup is measured by the mean number of interactions per bunch crossing. The distribution of this during Run 2 is shown below.
In order to properly simulate data with Monte Carlo, it is necessary to include the effects of pileup as seen in data. However, MC samples are often produced before data collection occurs, which means that the pileup profile of the corresponding detector data is unknown at the time of simulation. Additionally, if an analysis uses a non-standard GRL or a dynamically prescaled trigger, the data pileup profile will be unique to the analysis.
In order to correct the MC pileup profile to that of data, weights are applied to events to change the pileup profile. This reweighting changes the amount that each event contributes to the final distribution. This is done using a centrally provided tool.
Reweighting is a mathematical trick we use in many situations in ATLAS. By changing the weight of MC events, we can modify their relative contribution to various distributions. A weight greater than 1 increases the relative contribution of an event and a weight less than 1 decreases its contribution. Throughout your analysis, you will encounter many different weights that need to be applied to events. The total event weight is simply the product of all of the individual weights.
Pileup algorithm configuration via YAML
To schedule the pileup analysis algorithm, add the following lines to
the config.yaml file:
# Specify how to handle the pileup. The number of simultaneous
# collisions in the ATLAS detector creates pileup of events, the
# characteristics of which are determined by a pileup profile.
# This weights MC samples to have the same pileup profile as
# the collision data.
PileupReweighting: {}
{}. This is a quick way to let the parser know it shouldn’t expect anything other settings in this block, but everything is as expected.
The pileup reweighting tool generates and attaches a random run number to MC events. This random run number is used to assign MC events to different data taking periods and is used to determine the pileup weights that are applied as well as a variety of period-dependent procedures done by CP algorithms.
Test and commit your changes
Rerun your code to make sure you see printouts from the pileup block.
When you are happy this is running correctly, commit and push your changes.